Parallel-TMS

It's Friday afternoon and I am sitting here on the floor at the Museum Computer Network conference, held this year in Seattle. Yesterday Micah Walter and I presented the work leading up to and the plumbing (both technical and motivational) behind the alpha release of the new collections website at the Cooper-Hewitt.
Micah has posted his part of the talk, titled My mother invented put a bird on it
, on his website. This is what I said:

Hi, everyone. My name is Aaron. I am from the Cooper-Hewitt National Design Museum. I am newly arrived at the museum, as of July. Prior to this, I spent a couple years at Stamen Design in San Francisco mostly making maps and before that I spent about a thousand years at Flickr involved in all things geo and machine tag related.

I am also a member of the Spinny Bar Historical Society. We have new stickers this year, so come and find me after the talk if you’d like one.
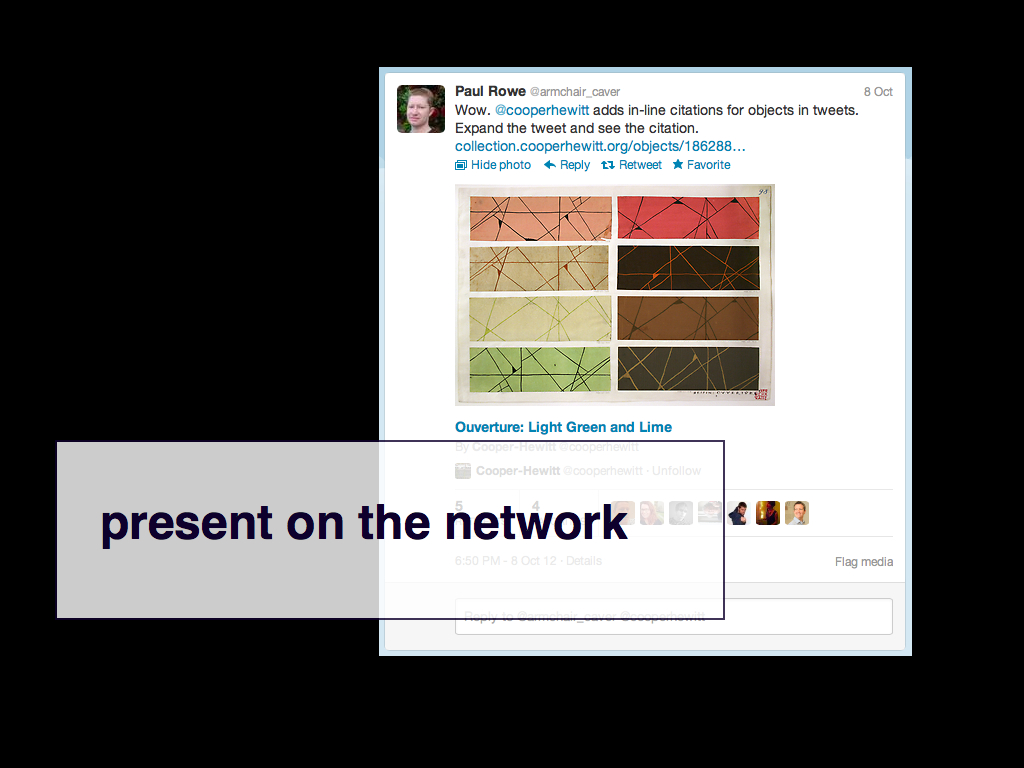
I am part of the Nerd Crew at Cooper-Hewitt and my job is to help imagine and then figure out how to build the tools and systems necessary to make the museum well-and-truly part of the internet.
We are closed until 2014 and we have the opportunity to rethink just about every aspect of our collection from the works themselves all the way down to the building. We are doing this at a time when, as both a practical necessity and a public good, we are moving away from a single narrative motive to a collection that speaks not only to scholars and experts but to casual visitors and amateurs and increasingly to the network itself.

Here's the tl;dr version of this talk:
TMS will remain the source of truth for the foreseeable future. eMuseum has been thrown under the bus.
We are writing our own tools, in-house, and we are building interfaces and indexes to tailored to our needs and not the abstract pony-soup of so many packaged solutions.
For those unfamiliar, TMS
is the 800 pound gorilla of the collections management space. eMuseum
is the t-shirt the gorilla wears when it surfs the web.
We are not building a platform for anyone other than ourselves. I realize this is tantamount to heresy for some in cultural heritage circles. I can live with that.
To the extent possible we will open source the relevant bits of our tool-chain where and when they are generic enough. We will discuss openly and plainly the approaches we've adopted, answer questions when they are asked and generally just share what we've learned.
But we are not writing a magic pony that your collection can jauntily mount and ride off in to the sunset on. It would be nice, I know, but it's also insane.
Every collection is a special snowflake. I don't say that as a pejorative. I say that because it's true and that uniqueness is what makes our collections valuable. And there is the very real fact that when you lift the hood on a collections management system, as I've now had the pleasure of doing, you realize they are as much tools for encoding and enforcing relationship management as they are anything else.
They are the place where the rules around who and what can be displayed, and when, are stored. They are place where the very real subtleties of human relationships and quirks are written down and we have more important things to do right now than try to build a battleship sized catch-all to attack that problem.

And there are lots of layers to this problem.
I mentioned that we are not getting rid of TMS any time soon. Whatever complaints people might have about TMS, whether they are voiced in public or in private, trying to tackle this piece of the puzzle is the very definition of non-trivial.
It is non-trivial because while there might be some technical challenges in modeling the underlying data in to and out of TMS the bulk of the work is going to be around the social interactions and the interface design of the software itself. It's a huge challenge and we would all benefit if someone took it on but it's not our mandate today.
Our mandate is the collection and the network and a future that is still best understood as a series of known unknowns. Put another way, we need to move faster than the dictates of eMuseum's pricing model or internal architecture or delivery schedules make possible.

So, how do you start? You start with the raw data so this is the part of the talk where I say critical things about TMS. I'm told, by many, that this is one of the seven deadly sins of museum professionals.
I guess I will find out but I also want to begin by stressing that: Working code always wins. Whatever issues I have with TMS today it's gotten us this far so it can't be all bad.
And in quiet moments when I stop and look at TMS as a system, rather than an immediate task to be completed, I see software from a time before we had big and fast hard drives, from a time before RAM was cheap. I see a system that had I been writing it back then too I probably would have made many of the same architectural decisions.
The problem is this, though: No one seems to know what happens to their data once it goes in to TMS.
Not with any confidence I can tell. No one has any idea what's going on in there and when you talk about people it you come away with the distinct sense that they are not so much talking about their data as the shadows their data casts from inside the system.
One reason for this, I think, is that TMS has indulged its clients — and that means us — in the idea of a single cross-institutional platform that hides the actual complexity of individual edge cases behind a twisty maze of pointers encoded in relational database tables.
But you'd think that the least you'd be able to do is dump them all to CSV files and work backwards from there.
Right?

The good news is that you can. The bad news is that it's not obvious. On any level.
Trying to get data out of TMS is some toxic stew of Windows networking hell, abstract pie-soup like ODBC, the vagueries of the ANSI SQL-92 standard and the spectacle of its instrumentation in MS SQL. Also Unicode errors.
The short answer to the problem is: Just use Perl.
If you're not already a Perl hacker hold your nose and enjoy the cold comfort that everything else is worse. Perl's database libraries – in particular DBI.pm – have been battle-tested for years now. And while they can't save you from some of the things I've described above they won't like Python's py-odbc library (when running on a 64-bit Mac) silently convert everything sent back from the database to ... UTF-16.

So far the biggest problem we've had is around the length of text fields. In particular the part where the database schema – the instructions for everyone else on what to expect – says that the maximum length for certain kinds text fields is ... -1.
This has a couple of interesting side-effects:
Unless you set DBI.pm 's LongTruncOk flag in then any data longer than 80 bytes will silently be truncated. This is a problem for both object descriptions and keyword fields, in TMS, that are abused for passing around institutional narratives. I'm pretty sure that this is an ANSI SQL-92 thing but I can't say for certain. Honestly, I can't stop pounding the table long enough to find out.
On the other hand if you unset the value then you need to explicitly say how big a text field *might* be because if the DBI code encounters something longer it promptly blows its brains out. As if that weren't bad enough, the only number that doesn't trigger this error is ... 2GB.
But only if you're doing your exports on a Mac. If you try to do the same thing, with exactly the same code, on a Linux machine then you don't get past the first row before Perl runs out of memory.
I'm still not able to get past my general rage and stunned disbelief that this happens at all to be able to tell you, with certainty, whose fault it is but it's basically all just unforgivable pendantry.

Other things we've noticed are that MS SQL uses binary timestamps which besides being the least useful (and possibly dumbest) date format ever created also make the CSV parsers cry. Oh, and apparently you can't have any columns in your database tables named External
. Like you, I wonder how it got in there in the first place.
All software is full of gotchas. That comes with the business so I'm not going to accuse TMS of deliberately promoting vendor lock-in but I do want to point out that this kind of relentless hoop-jumping just to get access to your own data has the same net effect. People are paralyzed with frustration and fear by the mechanics of TMS and more often than not they are unable to do anything with their own stuff.
That's really bad.

But you know, we've mostly got that nut cracked. Mostly. Enough at least to say: Onwards!

Our new collections website is built using an anti-framework called Flamework, which is really just a from-scratch rewrite of the core libraries and helper functions – a bag of tools – that were written at Flickr.
Flamework is still pretty much the domain of ex-Flickr engineers and is very much a work in progress, with individual pieces of functionality added on an as-needed basis. I've been doing a lot of work on top of Flamework, for the last couple of years, first for the Dotspotting project while I was at Stamen and since then for a number of personal projects like Parallel Flickr and Privatesquare.
This is not a sales pitch for Flamework. We're not, as I mentioned, here to sell you the Cooper-Hewitt collections platform. I only want to outline some of the choices we've made and why. We're just sharing shop-talk.

Flamework uses Apache, which seems to be largely out of favour these days. The argument is basically that it is too big and too bloated and generally makes spinning up quick and dirty web services a pain in the ass.
This is a valid criticism. But if you're building web applications I'm not really sure that anything else has tackled the minutiae of the problem with the thoroughness that Apache has. nginx is giving Apache a run for its money which is great but there's still a lot to be said for building on a foundation of boring, reliable software.
And it's worth pointing out that when people talk about web applications they're mostly talking around two specific things.

The first is dispatch, as in URL dispatch and pretty URLs. How a URL – which is a very real kind of interface – is connected to a discrete piece of functionality.
Apache uses mod_rewrite to do this. It's is both a blessing and a curse. mod_rewrite is as mysterious as it is insanely powerful. That alone is enough to drive people away and is part of the reason we've seen an explosion of bespoke URL dispatcher frameworks over the last couple of years.
mod_rewrite is weird and scary but, conceptually, it's also nothing more complicated than if this then that
. The problem is not with mod_rewrite but with the explosion of complexity that allowing someone to define arbitrary if-else-then rulesets affords.
Like Apache, I've not seen someone build a better 80/20 solution than mod_rewrite yet.

The second is an embedded programming language.
PHP is, it’s true, often as bad as everyone tells you. Except for the part where it is blazingly fast. In a way that no other language bindings for Apache, except native C code, are.
It has proven itself over and over and over again: Flickr, Facebook, Etsy and Yahoo have all built successful businesses on it for years now. I actually think that the root of most people's anger and dislike for Apache is that their programming language of choice (read: not PHP) doesn't work very well under Apache.
It wasn't supposed to be like that but it's pretty clear, in 2012, that PHP is basically Apache's native scripting language. Maybe not ideal but despite what people like to believe all programming is just typing so, again, onwards.

MySQL. Because it's fast. And it scales. Honestly we don't have a scaling problem – either in terms of traffic or the size of our collection – but one measure of our ambition is to have those problems.
Right now, it affords us an ability to shape the way we work with our collection quickly. We're still in that awkward getting-to-know-you stage of things with our data and not getting stuck in the quicksand of data modeling is paramount for us.

More importantly, and this is Flamework thing, we are not using an ORM. Which is just shop-talk for saying we write our own SQL. We don’t need code writing magic database queries for us. Partly because those queries are often poorly performant gibberish but mostly because, right now, we need to be close to the data. To understand it, intimately.

We will almost certainly end up using Solr in the future. It's entirely possible that the majority of the site will use Solr as its primary datastore. At the moment it's too soon. The time required to fuss with schemas and then to re-feed the indexes remains prohibitive and a bit of a waste.

Saying that, some of you may be wondering why we don't try using Elastic Search. We have. For those of you who don't know what Elastic Search is it's basically Solr with the added ability to index, and query, heterogeneous documents without a predefined schema. That is genuinely awesome and incredibly useful for spelunking through large and messy datasets. Like buckets of CSV files exported from TMS.

On the other hand Elastic Search uses a bespoke JSON syntax for doing any kind of sophisticated queries. Which means that the ability to actually query your data is tied to the vagaries of your programming languages's JSON serializer.
That part is not so good.

Deep breaths.

The point is that – and this quote is taken from the Flamework "statements of bias" – is the most important thing right now is: The speed with which the code running an application can be re-arranged in order to adapt to circumstances.

I started work, at the Cooper-Hewitt, on July 2. On September 27 we took down the old eMuseum website and replaced it with the new collections website, which is very much an alpha. There is a lot of work to do still but the site is meant to be a living, breathing example (read: running code) of the direction we're heading in.

Aside from all the stuff like persistent and stable identifiers and making almost everything a first-class resource on the web – of imagining every facet of our collection as URLs – one of the simpler things we've done is to add a random
button.
To make explicit a kind of literal random access memory to our collection.
The random button is scoped only those objects with one or more photos. That's really important for us and for any institution that hasn't finished digitizing their collection.
Most of our collection is still nothing more than "tombstone" data, much of it with incomplete descriptive data. That's fine. That's our history and we've proven that we get things done despite those shortcomings but we live and breathe this stuff in a way that most people don't.

We have a lot of stuff like this. This is not a joke. We have objects in TMS that don't have a title, that haven't been photographed, where we don't know who made it and we're not sure where it is. But we know it's a print. So essentially we know we have a piece of paper. Somewhere.
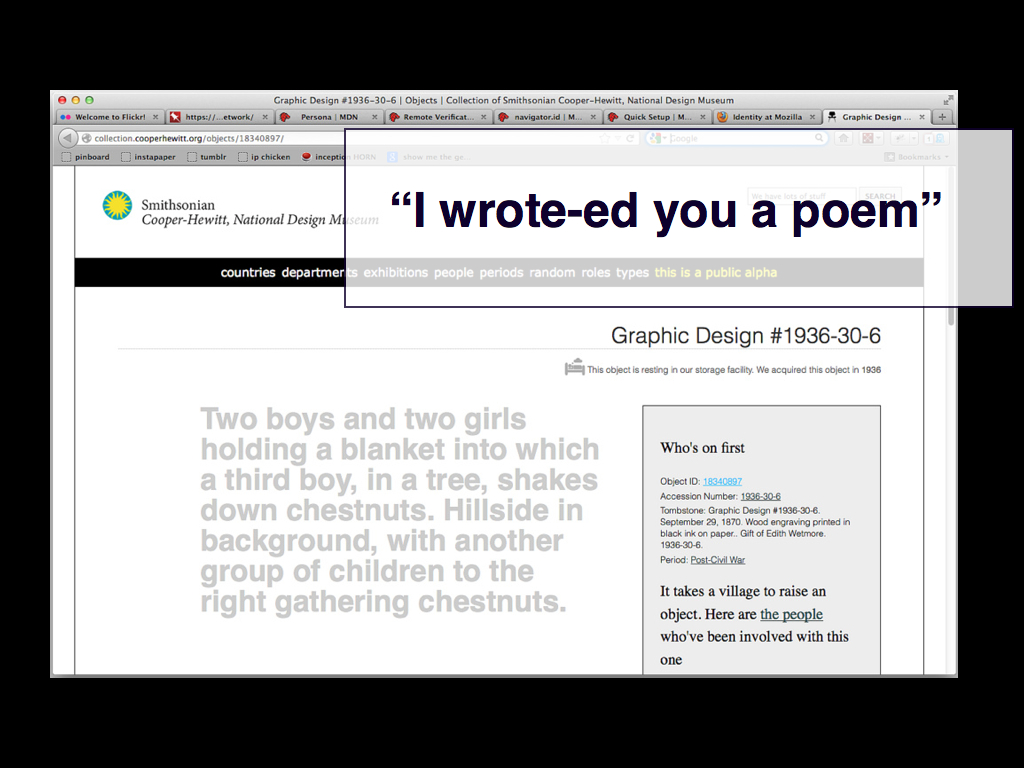
And stuff like this. This is the description for an object that hasn’t been digitized. It's lovely in its own way but you'd be forgiven for thinking that the Cooper-Hewitt had started collecting Markov bots.
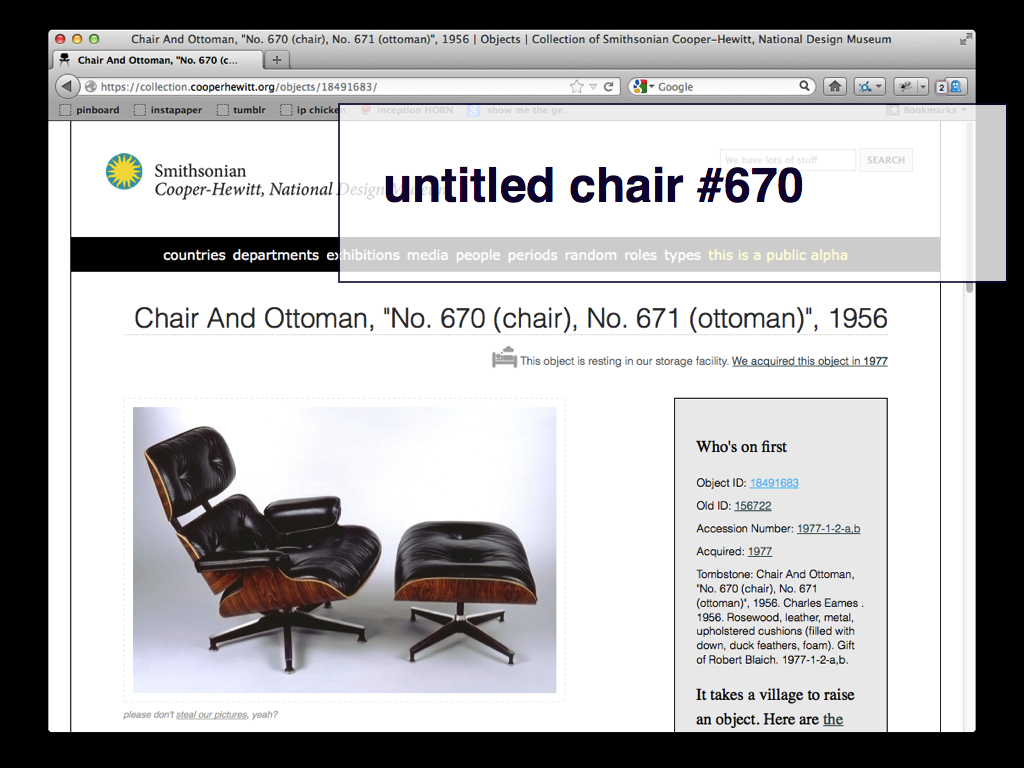
We know our data is weird. We know our data is incomplete. We'll fix it.
The point is that we are still feeling the shape of what's in there. All of this stuff has been locked away for so long, in the shadows of the database or in institutional histories, that we're going to have to spend some serious time digging it all out.
We will.

One of the ways we're trying to do this is by holding hands with other institutions and sources. We've been actively trying to build concordances between our data and projects like Wikipedia and Freebase and other cultural institutions like MoMA.
We've started with the people in our collection, the individual and corporations who've had a hand in the objects we steward. Eventually we'd like to do the same for topics and temporal periods and even for our objects.

Currently we're publishing concordances for about five sources but that's only because they were easy to get started with and they could be used to model interactions around.
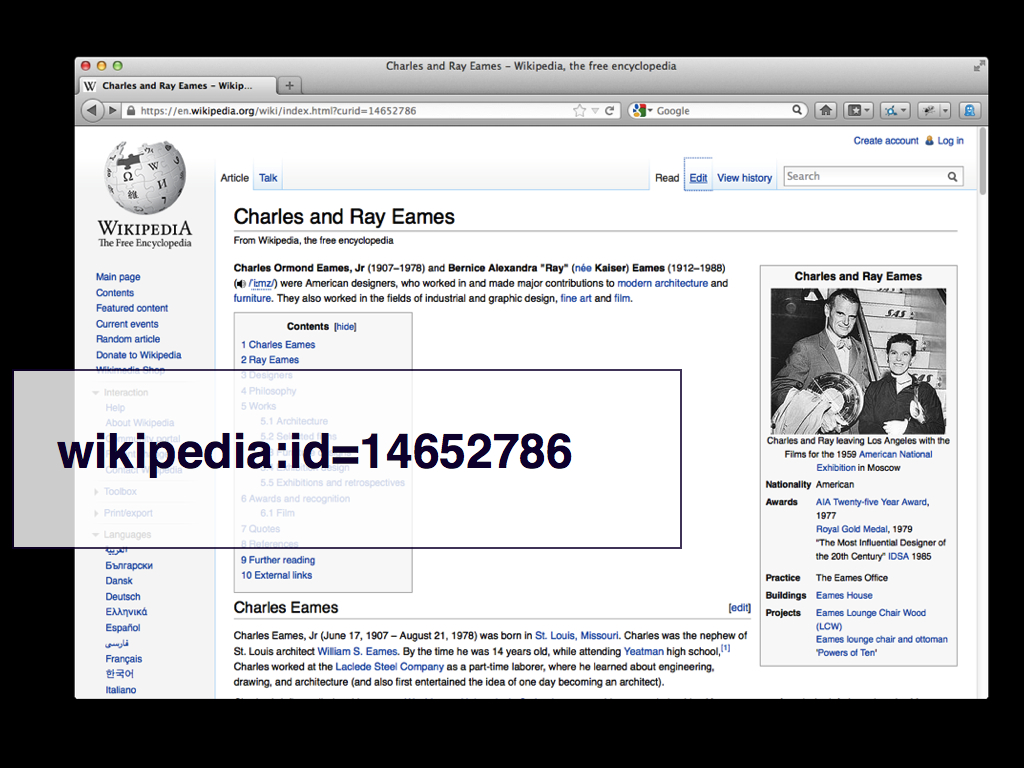
For example, we don't have a biography of Ray Eames. Arguably if there's anyone in our collection that we should be writing our own biographies for it's her. But we don't and that same measure doesn't necessarily apply to everyone in our collection. And for those people – maybe all the people – we need to ask the question: Why are we, each of us as institutions, burning time we could be using talking about the work we collect rewriting the same biographies over and over again?
Let's be honest and admit that in many instances the Wikipedia community is simply doing a better job of it. So yeah, of course we're going to build on, and celebrate, their contribution.

And even though we're not pulling in data from MoMA, the way we are with Wikipedia, because we are able to map artists in our respective collections we can in the immortal words of Seb Chan connect ours to theirs
.
That's sort of the whole point of internet, right?
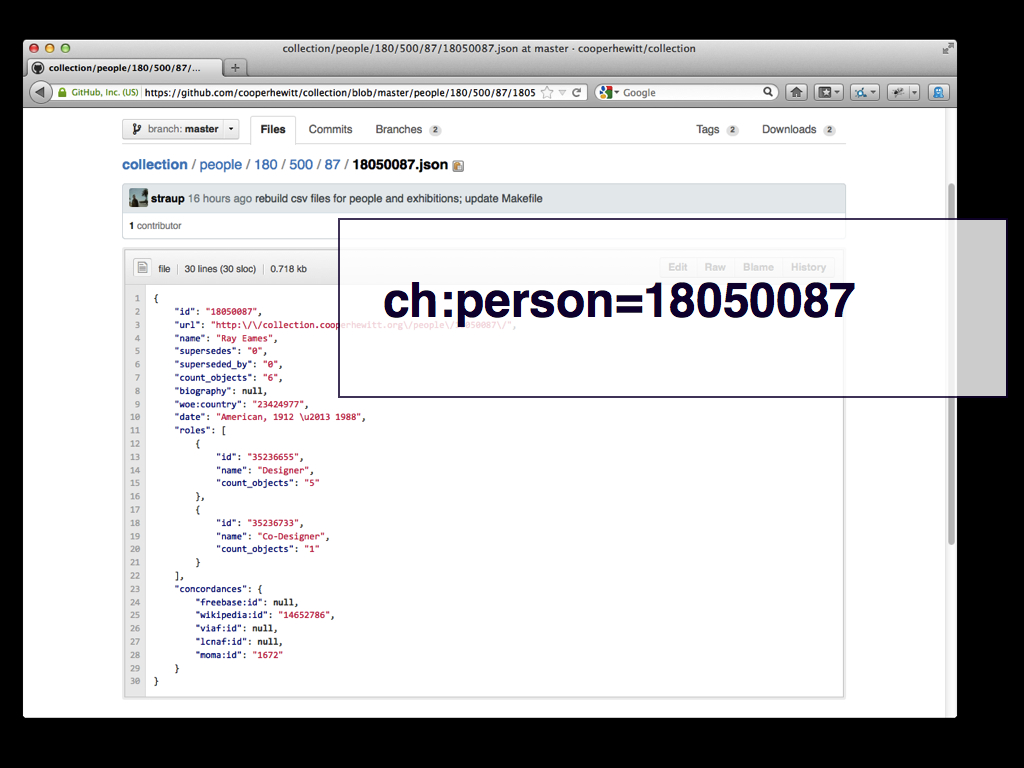
We've started publishing these concordances. We did the first release a couple of weeks ago in its own Github repository. That first release contained only those people in collection for whom we had at least one concordance. Honestly, I'm not sure what I was thinking when I did that.
Earlier this week we finally got around to publishing an updated version of our collections metadata dump on Github. There are now individual JSON blobs for all of the first class objects in our collection. This includes objects, people, exhibition, roles and so on. All the concordances or, more importantly, the lack of concordances.
We are standing up all of these things such that they can be present and addressable and accountable. The point is to increase the surface area for all of these parts of our collection so that they might grow texture and depth and, like I said, hold hands with the rest of the internet.

We're also in the process of night-light launching an API. The API is hiding in plain sight for people to use but is still experimental and currently targeted at the ongoing work we're doing around the renovation at the museum. I want to mention one thing in particular about the API, though. Both the API and the public Github releases are now generated using common code.
If you've not read Luke Dearnley's paper Reprogramming the Museum
about the disconnect the Powerhouse Museum experienced managing their public data downloads and their APIs, I highly recommend it. It is an experience that I've been mindful of as we go forward with all of this stuff and a big part of the motivation for ensuring that these two views on to our collection are always the same.
There is another aspect about the API that I didn't mention during the talk. Where it's necessary we've added two extra properties to records: supersedes and superseded_by. Currently they all have the same empty value (0) but as we go forward with the data clean up we will update the records with bunk or obselete data with pointers to the new record. And vice versa. This is a relatively small tweak but we think it's an important addition that will prove its value in the long run.

So that's where we are, four months in. There's a lot left to do and there's a lot we haven't figured out yet. This is the work. It's hard work. But the point is to work on the hard things because they are important.

Finally if there's anyone here not already aware of the work being done by the team at the UK Government Digital Services office go now, right now, and check out what they've been up to. They are doing the best work on the web, at the moment. The ambition and the execution of their work around the gov.uk site and their willingness to speak openly and frankly about the sausage making behind it is inspiring.

Thank you.
This blog post is full of links.
#parallel-tms